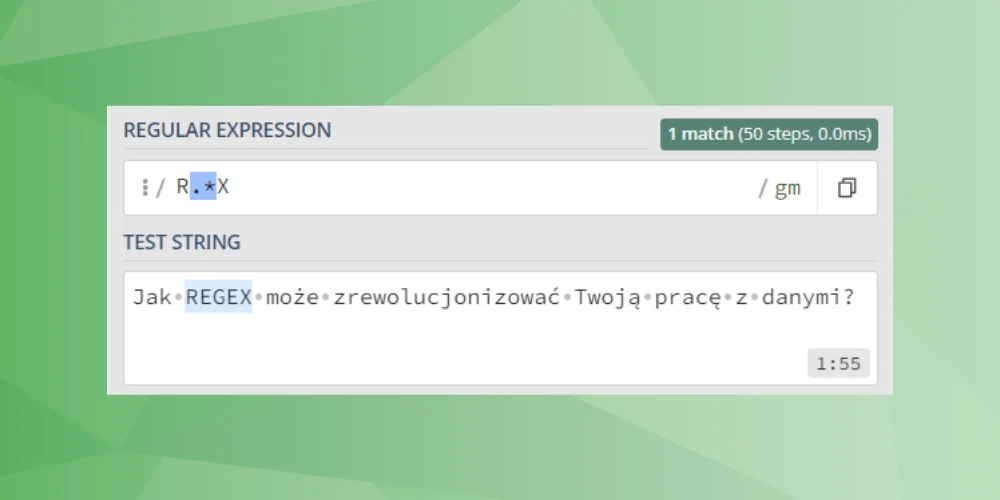
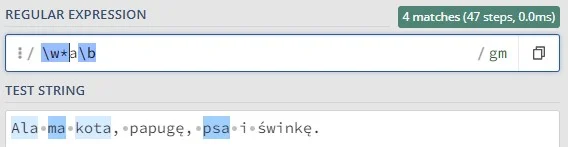
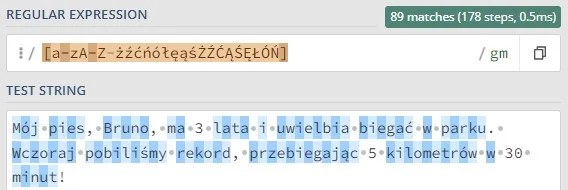
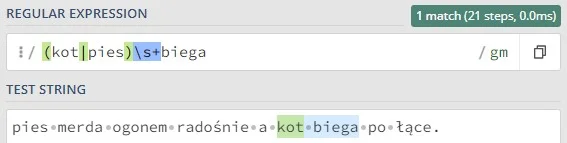
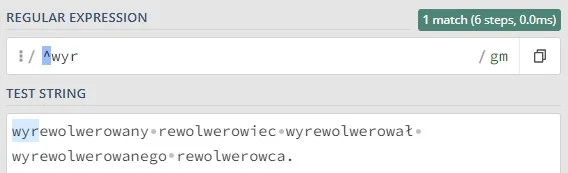
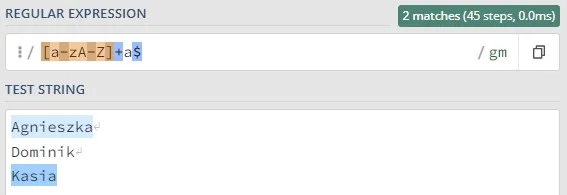
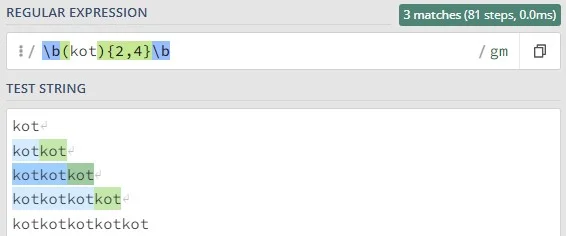
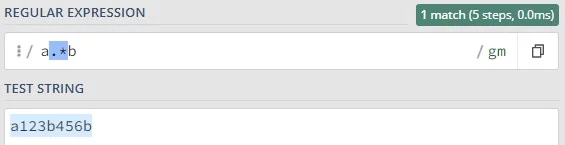
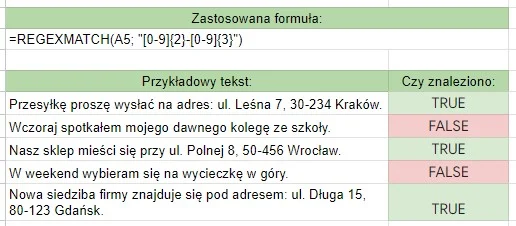
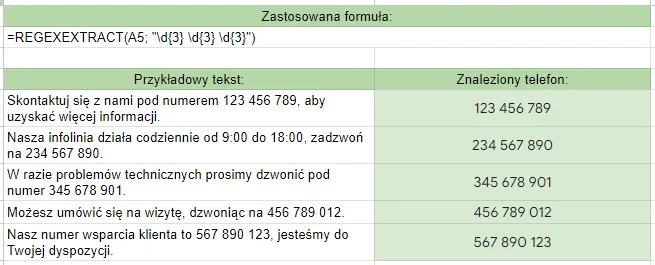
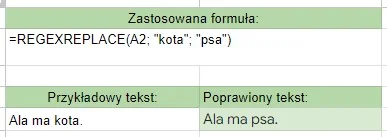
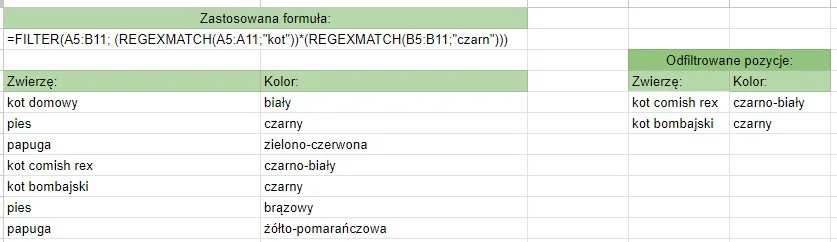
To symbole, które określają liczbę wystąpień danego elementu (litery, sekwencji znaków, grupy znaków). Innymi słowy, precyzują, ile razy dany fragment wzorca ma być znaleziony w tekście. Domyślnie kwantyfikatory są chciwe (greedy), co oznacza, że dopasowują jak najdłuższy ciąg znaków spełniający wzorzec.
x* – zero lub więcej powtórzeń x
x+ – jedno lub więcej powtórzeń x
x? – zero lub jedno powtórzenie x
x{2} – dokładnie dwa powtórzenia x
x{2,} – dwa lub więcej powtórzeń x
x{2, 5} – od dwóch do pięciu powtórzeń x